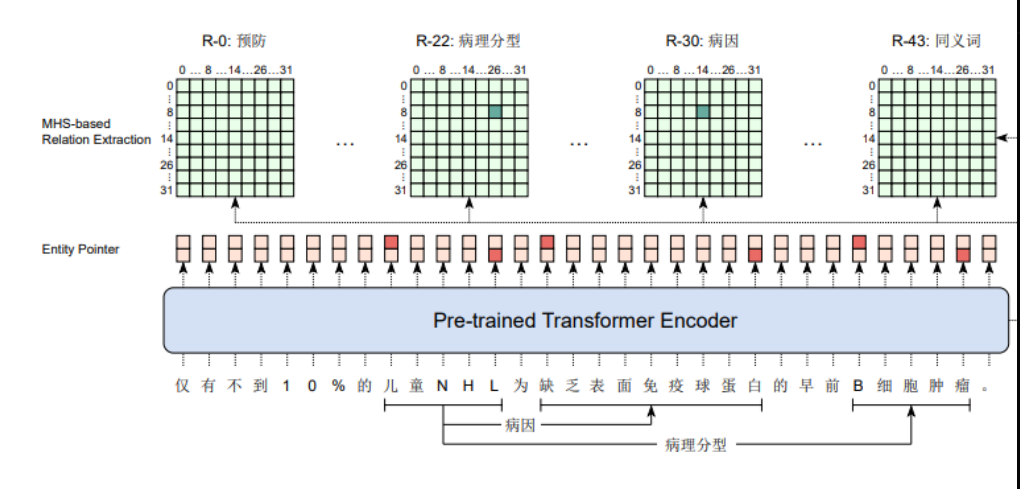
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径及一点个人思考
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
接口使用
python">import ask_Tongyi
import ask_Wenxin
import ask_Xunfei
import pandas as pd
import numpy as np
# llm = ask_Tongyi.TongyiAPI()
# llm = ask_Wenxin.WenxinAPI()
llm = ask_Xunfei.XunfeiAPI()
data = pd.read_excel(r'C:\Users\12258\Desktop\123\线上API和14B性能对比.xlsx')
prompt_ls = data['Docs'].tolist()
question_ls = data['Question'].tolist()
n = len(data)
anwser_ls = []
for index in range(n):
# for index in range(1):
single_query = prompt_ls[index] + '\n' + question_ls[index]
single_anwser = llm.get_one_response_by_prompt(single_query)
print(single_query)
print(single_anwser)
anwser_ls.append(single_anwser['text'])
pd.DataFrame(anwser_ls).to_excel(r'C:\Users\12258\Desktop\123\xunfei_anwser.xlsx',index=False)
文心一言
python">import requests
import json
class WenxinAPI:
def __init__(self):
self.API_KEY = '*'
self.SECRET_KEY = '*'
self.token = self.get_access_token()
def get_access_token(self):
"""
使用 API Key,Secret Key 获取access_token,替换下列示例中的应用API Key、应用Secret Key
"""
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api}&client_secret={secret}".format(api=self.API_KEY,secret=self.SECRET_KEY)
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response.json().get("access_token")
def get_one_response_by_prompt(self, question):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-3.5-8k-0205?access_token=" + self.token
payload = json.dumps({
"messages": [
{
"role": "user",
"content": question
}
]
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return {'text':json.loads(response.text)['result']}
if __name__ == '__main__':
test_query = '你是谁'
llm = WenxinAPI()
anwser = llm.get_one_response_by_prompt(test_query)
print(anwser)
讯飞星火
需要一个引用文件:SparkApi.py
python">import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket # 使用websocket_client
answer = ""
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.Spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
# print("### error:", error)
pass
# 收到websocket关闭的处理
def on_close(ws,one,two):
# print(" ")
pass
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, domain= ws.domain,question=ws.question))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
# print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
# print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
global answer
answer += content
# print(1)
if status == 2:
ws.close()
def gen_params(appid, domain,question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"random_threshold": 0.5,
"max_tokens": 8192,
"auditing": "default"
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
def main(appid, api_key, api_secret, Spark_url,domain, question):
# print("星火:")
wsParam = Ws_Param(appid, api_key, api_secret, Spark_url)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open)
ws.appid = appid
ws.question = question
ws.domain = domain
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
python">import requests
import json
import SparkApi
class XunfeiAPI:
def __init__(self):
self.appid = "*"
self.api_secret = "*"
self.api_key = "*"
self.domain = "generalv2"
self.url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0
def getText(self, text, role, content):
'''
获取角色和文本存入text中
'''
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def get_one_response_by_prompt(self, question):
SparkApi.answer = ""
SparkApi.main(self.appid, self.api_key, self.api_secret, self.url, self.domain, self.getText([], "user", question))
return {'text':SparkApi.answer}
if __name__ == '__main__':
test_query = '你是谁'
llm = XunfeiAPI()
anwser = llm.get_one_response_by_prompt(test_query)
print(anwser)
通义千问
python">import requests
import json
import dashscope
from dashscope import Generation
from http import HTTPStatus
class TongyiAPI:
def __init__(self):
API_KEY = 'sk-*'
dashscope.api_key = API_KEY
self.gen = Generation()
def get_one_response_by_prompt(self, prompt):
response = self.gen.call(
model=dashscope.Generation.Models.qwen_turbo,
prompt=prompt
)
# The response status_code is HTTPStatus.OK indicate success,
# otherwise indicate request is failed, you can get error code
# and message from code and message.
if response.status_code == HTTPStatus.OK:
# print(response.output) # The output text
print(response.usage) # The usage information
return response.output
else:
print(response.code) # The error code.
print(response.message) # The error message.
GPT
通过openai-sb调用
python">import requests
import json
import openai
class GPTAPI:
def __init__(self):
self.API_KEY = 'sb-*'
self.url = 'https://api.openai-sb.com/v1/chat/completions'
openai.api_key = self.API_KEY
openai.api_base = 'https://api.openai-sb.com/v1'
def getText(self, text, role, content):
'''
获取角色和文本存入text中
'''
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def get_one_response(self, question):
payload = json.dumps({
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": question
}
]
})
headers = {
'Authorization': "Bearer "+self.API_KEY,
'Content-Type': 'application/json'
}
response = requests.request("POST", self.url, headers=headers, data=payload)
try:
return response.json()['choices'][0]['message']['content']
except Exception as e:
print(e)
return ''
def get_one_response_by_prompt(self, prompt):
payload = json.dumps({
"model": "gpt-3.5-turbo",
"messages": prompt
})
headers = {
'Authorization': "Bearer "+self.API_KEY,
'Content-Type': 'application/json'
}
response = requests.request("POST", self.url, headers=headers, data=payload)
return response.json()
if __name__ == '__main__':
test_query = '你是谁'
llm = GPTAPI()
anwser = llm.get_one_response_by_prompt(test_query)
print(anwser)